
今天我們先進入 How Google does Machine Learning 的第五章節,之後再回到第四章~
這次鐵人賽的30天中,我目前所寫文章的所有課程目錄如下:
第五章節的課程地圖:(紅字標記為本篇文章中會介紹到的章節)
Module Introduction
Cloud Datalab
Cloud Datalab
Demo: Cloud Datalab
Development process
Demo of rehosting Cloud Datalab
Working with managed services
Computation and storage
課程地圖
這章基本的用文字介紹了一下雲端的環境,
我們會用python notebook做機器學習的開發,
而notebook的服務在google雲端上。
Cloud Datalab基本上是本章節使用的開發環境,
而此服務在VM上運行,包含python notebook,
我們同時也會教學Compute Engine的原理與Cloud Storage的知識。
既然是VM就必須提調VM的兩個特性:
例如:添加GPU或增加更多memory
而這點最方便的方法就是使用Cloud Storage。
我們將notebook的內容保存在Cloud Storage中,
同時還能達到版本控制的效果。
而這個章節的學習目標,我們可以參考如下:
Module Learning Objectives(這個module的學習目標)
練習使用notebooks完成資料科學的任務
在雲上使用notebooks,並更改硬體規格
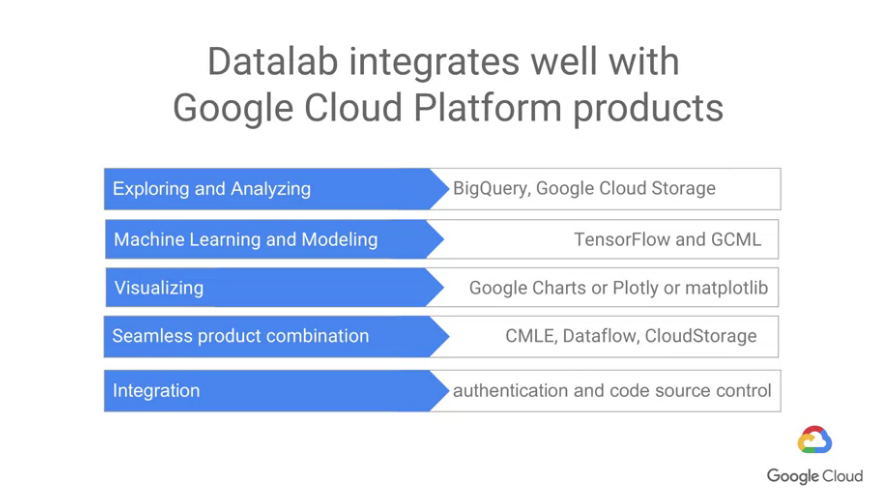
我們將將Cloud Datalab與BigQuery一起使用,BigQuery是雲上的數據分析服務,可以讓超越傳統數據庫的執行速度與規模進行queries的查詢
能使用一些pre-trained ML models(前面的章節有介紹到),並在Cloud Datalab中運行。

課程地圖
這章稍微介紹了一下Datalab的環境,以jupyter作為基礎的open source平台。
下面為Datalab的介面展示:
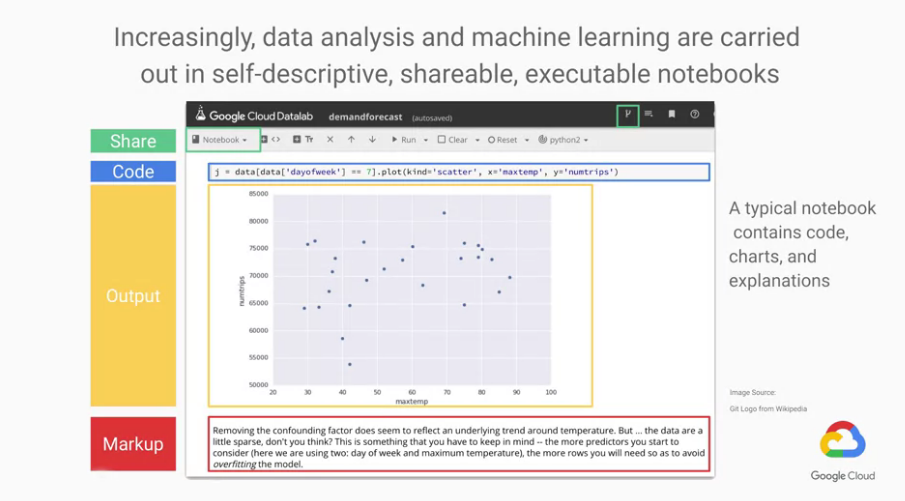
可以看到主要有三個部分:code, output, markup sections彼此交錯
也因為這樣的交錯才能使notebook如此實用,
code:
在此打你的python code
執行code的方式: 按shift+enter或 按上方的Run botton
output:
注意output可以為圖形,不像command line一樣。
markup:
可以寫一些markup(markdown語法),可以解釋你這個部分在做什麼。
最後是綠色部分:
有可以將notebook匯出的按鈕,可以將此notebook下載下來。
可以commit code至Google Cloud Platform至code repository的按鈕。Clear all: 清除所有outputRun all Cells: 執行所有Cells
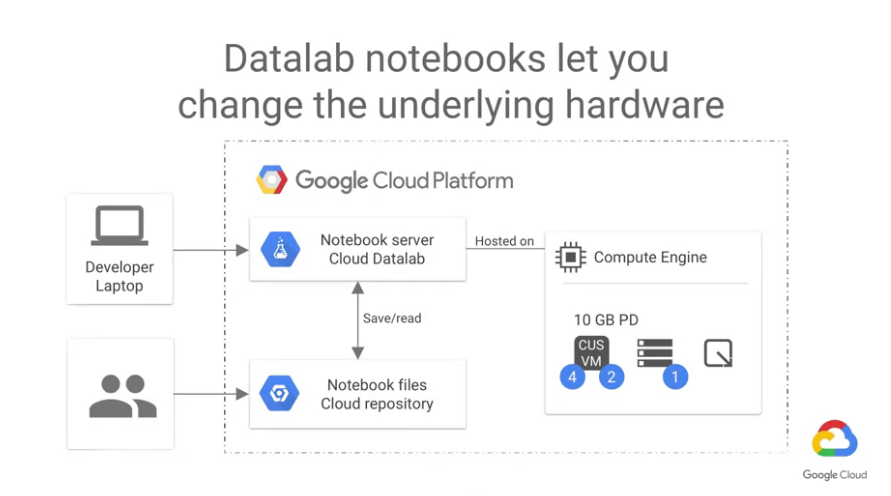
所以整個Datalab的使用流程大概可以表示成下圖:
另外要特別強調的是,Datalab的一大特色是可以線上協同合作
傳統的notebook要線上合作有個基本的問題,誰當host?
一但host只要關機,任何人都無法繼續工作。
而Datalab解決了這個問題,而我們只要給一個URL就可以了。
另外一種Share的方式可以利用版本控制系統,例如Git,
而且只要我們想改動硬體的規格,任何人都可以直接改好後,
重新啟動VM,就直接以新的硬體規格來執行程式。
簡單來說,Datalab架於雲端的VM上,任何人只要連線即可開始工作。
而只要工作結束了,隨時也能將此VM刪除。
課程地圖
這個章節主要來介紹如何在Datalab中更換VM的硬體規格。
Step1. 先將想更改規格的VM打勾,上方按下暫停VM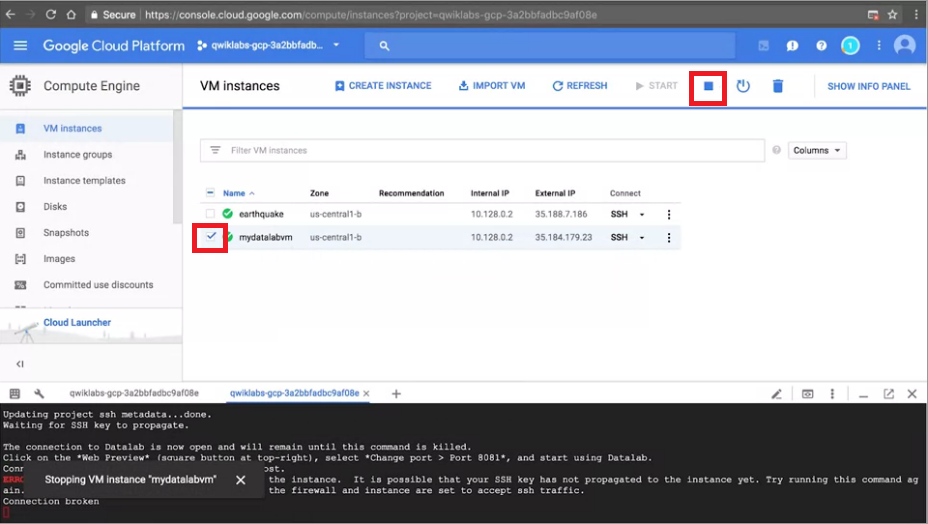
Step2. 點選Edit,在方框處更改想要的硬體規格,記得在下方按"Save"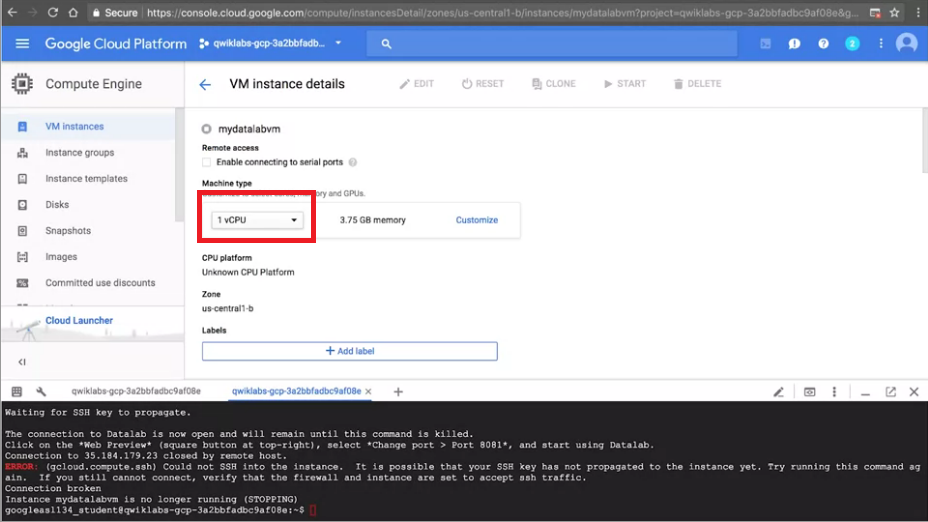
Step3. 點選要重啟的VM,按上方Start,確認重新Start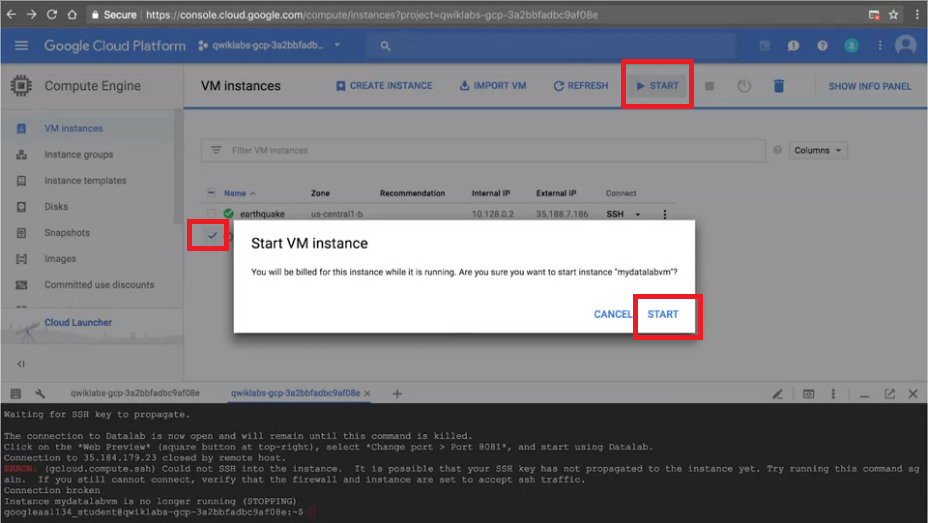
小提示:在未來的lab中,我們只需要用到"n1-standard-1 VM"(basic plain vanilla virtual machine)的硬體規格,就已經非常足夠執行我們所要的程式。
課程地圖
這個章節會介紹透過雲端執行ML時的大致流程。
以讀取CSV file作舉例,如果是一般的處理方式,
首先我們將CSV file可以透過Pandas and Apache Beam進行資料前處理,
再丟入至Tensorflow進行訓練,透過訓練使其不斷的進步。
如果同樣的例子透過GCP的方式進行處理,
首先用Google Cloud Storage儲存資料,用Cloud Dataflow進行資料前處理,
再用Cloud Machine Learning進行訓練,透過Cloud ML Engine進行參數最佳化。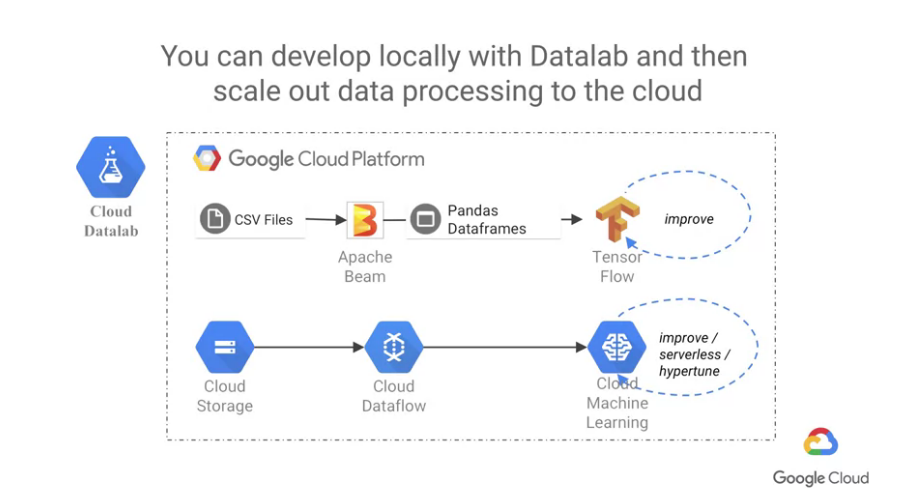
使用GCP就能產生與其他GCP產品一樣的效果,
而且數千台機器同時探索並分析數據,
而且就算已經習慣使用如Pandas, Seaborn 或 Plotly之類的工具,
也能夠直接在GCP使用,透過API直接串連起來。
Compute Engine
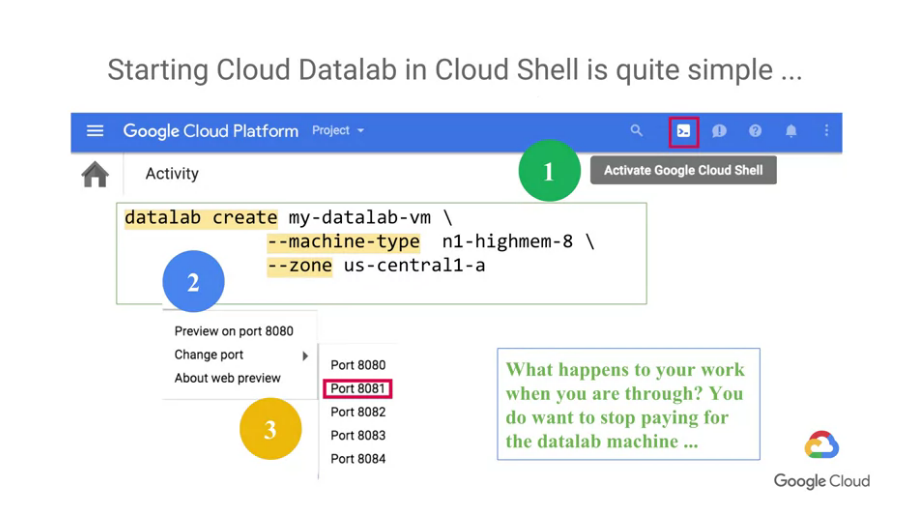
先去Cloud Shell並輸入"datalab create",並設定一些參數,
例如compute zone, machine type,這些都屬於Compute Engine。
Compute Engine是一種向雲端租借的機器(VM),所以也代表不用永久擁有。
當VM消失時,在此機器上的工作也會消失,
因此我們還會在下一個章節中介紹Cloud Storage的知識,
Cloud Storage就是透過雲端來幫助我們儲存這些資料的地方,避免資料遺失。
課程地圖
這個章節會介紹Compute Engine的原理與Cloud Storage的知識,
了解Compute Engine可以清楚我們是怎麼在雲端運算的,
了解Cloud Storage則可以清楚資料是怎麼儲存的。
Compute Engine基本上可以想像成是分散在世界各地的CPU,
而Cloud Storage則是分散在世界各地的儲存裝置(硬碟)。
Compute Engine
Datalab雖然是一個Compute Engine所執行的,
但我們可以客製化我們的Compute Engine,
例如:幾核心電腦、有多少memory、硬碟有多少容量、作業系統
而這些設定皆可以修改,不用太擔心一開始的設定值。
VM上的disk速度非常快,但當VM消失時,disk也會消失。
Cloud Storage
而Cloud Storage是持久的,也就是說放在Cloud Storage的資料會被複製存儲在多個位置。
我們可以透過任何電腦取得這些資料,並直接讀取內容。
而Google Center的網路以petabit bisectional bandwidth速度在通信,
這也代表著十萬台機器可以以每秒10 gigabits的速度在相互通信。
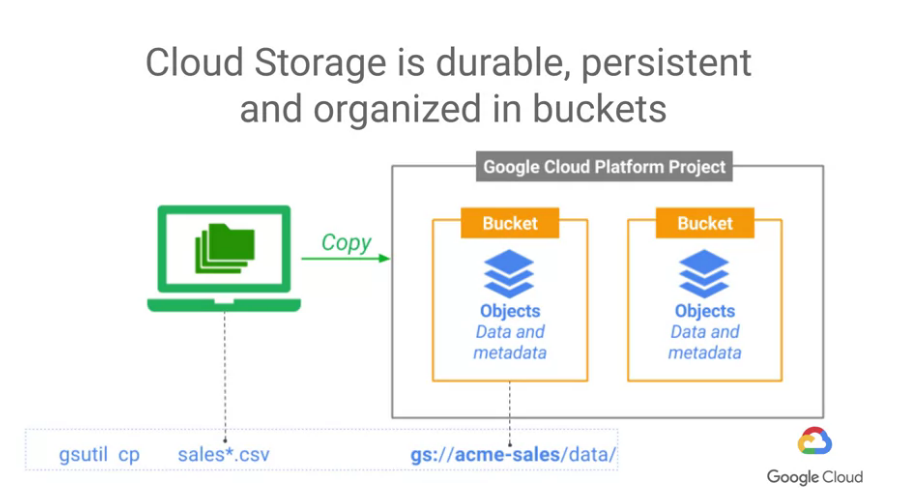
我們來談一下資料在雲上的形式,
一個典型的Cloud Storage URL可能看起來像gs:acme-sales/data/sales003.csv,
我們稱這樣的資料存儲為"bucket",bucket的名稱是全球唯一的,
就像是domain name或internet URL一樣,
基本上除非真的非常不幸,否則bucket的名稱很難已經被使用。
Compute Engine與Cloud Storage的連結方式:
gs URL 就像是一個資料結結構一樣,一個gs URL對應一個在Cloud Storage的物件
我們可以使用gsutil來取用他,這是一個給command line用的工具,
我們可以透過Google Cloud SDK下載到他,
雲端上的Compute Engine已經內建好gsutil了。
如果是想在自己的電腦使用,可以去下載Google Cloud SDK,裡面包含gsutil的功能。
Gsutil 也使用大家所熟悉的 Unix command line的表示方式:
像是 MB 與 RB 代表著"建立bucket"與"移除bucket" (這個真的滿有熟悉感的
)
或 CP 代表著"copy"
如果不使用command line,也可以使用GCP console 或 programming API, REST API
我們示範一個複製大量檔案作為例子,我們將sales*.csv複製到一個特別的Cloud Storage位置
(註:我們前面提到Cloud Storage buckets是耐久的,也就表示這資料會被重複儲存至多個位置。)
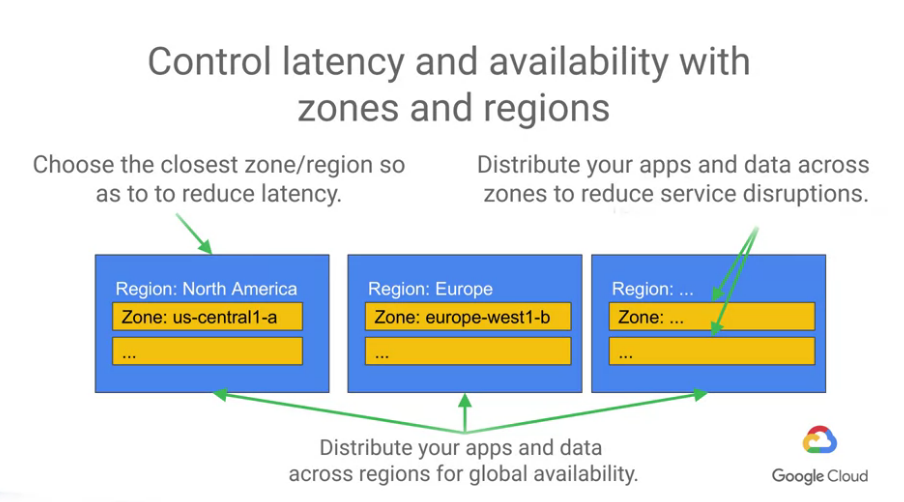
不過這裡要提醒的是,雖然資料被儲存在多個位置,但不代表不用在意"網路延遲問題",
可以的話還是盡量把資料儲存在計算的位置附近。
另外一個情況是可能有時會有區域的伺服器故障,
我們應該要分散apps與data至多個zones以保護這樣的情況,
一個zone故障了,可以即時調用附近的zone來接續服務。
zone是分散在一個regions的不同位置,被命名為region name-a zone, letter,
而當我們將做一個全球可用的app,
我們就可以考慮分散apps與data在不同的regions,來為全球的客戶提供服務。
coursera - How Google does Machine Learning 課程
若圖片有版權問題請告知我,我會將圖撤掉
